Interests: Network analytics, Graph Databases, GIS (spatial) Analytics, Fraud Detection, Data visualisation, Data Sciences, Data quality, Email reliability, Social Media.
Publications
-
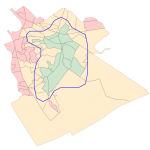
Peut-on toujours atteindre une maternité en 30 minutes ? (partie 2)
Dans notre article précédent, nous avons montré comment il était possible de calculer la zone accessible dans un délai donné à partir d’un ensemble de points de départ (ou d’arrivée), comme une maternité, un départ SMUR ou un centre de vaccination Covid. Les cartes présentées ont le grand avantage de donner une très bonne vue
-
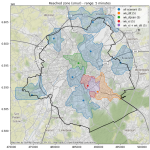
Peut-on toujours atteindre une maternité en 30 minutes ?
Peut-on, de partout en Belgique, atteindre une maternité en moins de 30 minutes en voiture ? Si certaines maternités fermaient, quel en serait l’impact ? Le gouvernement Bruxellois a décidé de ne pas ouvrir de centre de vaccination Covid dans le sud-est de Bruxelles (Watermael-Boitsfort et Auderghem) : quel est l’impact en termes d’accessibilité ?
-
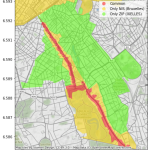
La jointure spatiale, la clé de l’analytique géographique
Dans cet article, nous allons explorer un concept fondamental de l’analytique géographique (GIS Analytics) : la jointure spatiale. Cet article est accompagné d’un notebook Python (lien git – lien nbviewer), permettant à chacun d’approfondir la question et de manipuler les différents exemples. La jointure spatiale est l’équivalent géographique de la jointure classique, ou attributaire, que
-

Le web scraping : utile pour l’eGov ?
Le web scraping, parfois appelé web crawling ou web harvesting, reprend toutes les techniques d’extraction de contenu sur des sites web, au moyen d’outils (scripts, programmes, plugins…) dans le but de son utilisation dans un autre contexte. Cette extraction se fera sans que des outils dédiés aient été proposés par les propriétaires du site web,
-

Webscraping for Analytics
Présentation donnée lors du webinaire “Webscraping – by Smals Research” du 30/06/2020. Le Web scraping/crawling/harvesting est un technique d’extraction de contenu sur des sites web, au moyen de scripts/programmes, dans le but de son utilisation dans un autre contexte. L’utilisation de web scraping est très large, avec relativement peu de contraintes. Dans sa présentation, Vandy
-
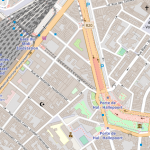
Géocodage : contourner les lacunes d’OpenStreetMap (partie 2)
Dans notre article précédent, nous présentions les difficultés que nous avons rencontrées dans notre tentative de géocoder (convertir une adresse en coordonnées géographiques, et standardiser cette adresse) avec Nominatim, le géocodeur d’OpenStreetMap. Nous avons aussi évoqué qu’en modifiant légèrement les adresses que Nominatim n’avait par reconnues, elles le devenaient. Nous avons considéré un ensemble de
-
Géocodage : contourner les lacunes d’OpenStreetMap (partie 1)
Pour divers clients, nous avons été à la recherche d’une solution permettant de nettoyer (standardiser) des adresses postales, principalement en Belgique. Nous avions besoin d’une solution « on-premise », idéalement en Open-Source. Nous avons voulu construire une solution basée sur OpenStreetMap, qui permettait de rencontrer ces deux contraintes. Mais il s’est vite avéré qu’OpenStreetMap n’était
-

Data quality : mesurer la similarité interne
Dans notre article précédent, nous présentons une méthode permettant de mesurer et visualiser l’importance des valeurs rares dans une liste de données où l’on s’attend à une grande redondance, souvent signes d’un problème de qualité. La méthode en question se basait uniquement sur un comptage des occurrences des valeurs, sans du tout en examiner le
-

Scrapy – web scraping framework
Scrapy est un framework écrit en (et pour) Python permettant de faire du web-crawling (ou web-scraping), c’est-à-dire de l’extraction automatique de contenu à partir de pages web. Une grande partie du travail du web-crawling est gérée automatiquement par le framework. Pour des cas simples mais réalistes, le code (Python) à écrire peut se limiter à
-
Data Quality : mesurer les valeurs rares
Des données, à partir du moment où elles vivent et sont alimentées, souffrent presque systématiquement de problèmes de qualité. Le domaine de la Qualité des données (Data Quality) est vaste, très actif tant dans le monde académique qu’industriel. Il y a bien évidemment des aspects méthodologiques (améliorer les processus pour que les données qui rentrent
Keywords:
analytics Artificial intelligence big data blockchain BPM chatbot cloud computing cost cutting cryptography data center data quality EDA egov Event GIS governance Information management Machine Learning Managing IT costs methodology Mobile Natural Language Processing Open Source Privacy Productivity Security social software design software engineering standards