analytics
-

Graphtechnologieën, de toepassingen ervan en tools: een overzicht (deel 2)
Dit tweede deel is gewijd aan graph databases en aan knowledge graphs, hun verschillen en tools.
-
Graphtechnologieën, de toepassingen ervan en tools: een overzicht (deel 1)
Dit eerste deel richt zich op graphs in hun fundamentele wiskundige vorm.
-
Les technologies graphes, leurs applications et leurs outils: un tour d’horizon (Partie 2)
Cette seconde partie est consacrée aux bases de données orientées graphe et aux graphes de connaissances.
-
Les technologies graphes, leurs applications et leurs outils : un tour d’horizon (Partie 1)
Cette première partie est consacrée aux graphes dans leur forme mathématique fondamentale.
-
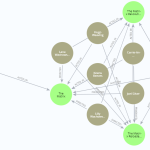
Een graph database verkennen
Sinds 2017 vestigen we op deze pagina’s de aandacht op het gebruik van Graph Databases (hier, hier en hier). Gartner voorspelt dat in 2025 de graph-technologieën zullen worden gebruikt in 80% van de innovaties in het gebied van data en analytics, tegenover 10% in 2021, waardoor snelle besluitvorming in een organisatie mogelijk wordt.
-
Explorer une base de données orientée graphes
Depuis 2017, nous mettons en avant dans ces pages (ici, là, ou encore ici) l’utilisation de bases de données orientées graphes (ou Graph Databases). Gartner prédit que d’ici 2025, les technologies graphes seront utilisées dans 80 % des innovations en données et analytique, contre 10 % en 2021, facilitant la prise de décision rapide au travers d’une organisation.
-

Fake it till you make it – an introduction to synthetic data
Slides van de webinar voor Smals Academy op 01/12/2022 (texte français : voir ci-dessous) Een synthetische dataset is een fictieve dataset die de kenmerken van een echte dataset zo goed mogelijk nabootst. Een correct samengestelde synthetische dataset kan, omdat het om louter fictieve gegevens gaat, probleemloos gedeeld, hergebruikt of gepubliceerd worden. Zo kan de toegang tot
-

Honey, I scraped the kids – over taalmodellen en privacy
De datasets die ten grondslag liggen van enorme taalmodellen zijn zonder veel poespas gescraped van het internet. Een korte zoektocht naar persoonsgebonden gegevens hierin, brengt al snel heel wat boven water.
-

Data scrambling: synthetische data in de praktijk
In dit artikel kijken we naar de praktische bekommernissen als we tools voor synthetische data inzetten: wat komt een data professional die hiermee aan de slag moet zoal tegen?
-

Leximancer – Tekstuele analyse
Leximancer is een commerciële tool die uit een grote hoeveelheid tekst de belangrijkste onderwerpen identificeert, deze groepeert in gerelateerde concepten, en de relaties ertussen visualiseert. De gebruiker kan bij elke tussenstap de resultaten verfijnen. Mogelijke toepassingsdomeinen zijn digitaal forensisch onderzoek of inspectie, analyse van grootschalige bevragingen, of pers- of literatuurreviews. Leximancer est un outil
Keywords:
analytics annexe_category Artificial intelligence big data blockchain BPM chatbot cloud computing cost cutting cryptography data center data quality development EDA egov Event GIS Knowledge Graph Machine Learning methodology Mobile Natural Language Processing NLP Open Source PaaS Privacy Productivity quantum computing Security software design