[FR]
-

Named Entity Recognition : une application pratique du NLP
Dans le secteur public, les administrations font face à un nombre considérable de documents à gérer. Ces documents doivent être indexés et organisés tel qu’il soit possible de retrouver facilement de l’information. Dans ce contexte le NER ou Named Entity Recognition, une technique basée sur le machine learning et le Natural Language Processing (NLP), est une solution particulièrement intéressante. Cela…
-

NLP & modèles de langage
Ce blog introduit les modèles de langage statistiques qui sont nécessaires à la résolution de nombreux problèmes liés au traitement automatique du langage naturel ou NLP (Natural Language Processing). Parmi ces problèmes, on peut citer la traduction automatique, la reconnaissance vocale, les systèmes de questions-réponses, l’optical character recognition (OCR) et les problèmes de génération de langage naturel en général. Qu’est-ce…
-

Data quality : mesurer la similarité interne
Dans notre article précédent, nous présentons une méthode permettant de mesurer et visualiser l’importance des valeurs rares dans une liste de données où l’on s’attend à une grande redondance, souvent signes d’un problème de qualité. La méthode en question se basait uniquement sur un comptage des occurrences des valeurs, sans du tout en examiner le contenu. Classiquement, pour standardiser des…
-
Data Quality : mesurer les valeurs rares
Des données, à partir du moment où elles vivent et sont alimentées, souffrent presque systématiquement de problèmes de qualité. Le domaine de la Qualité des données (Data Quality) est vaste, très actif tant dans le monde académique qu’industriel. Il y a bien évidemment des aspects méthodologiques (améliorer les processus pour que les données qui rentrent soient les plus “propres” possible),…
-

Anomalies & Transactions Management System (ATMS) : enjeux, concepts, réalisations et travail en cours
Cet article de blog a pour objet d’introduire le concept d’ATMS (Anomalies & Transactions Management System) : après en avoir montré l’importance fondamentale dans le cadre du « back tracking » récemment évoqué dans un article de blog de mai 2018, nous en rappelons les principales références ; nous en évoquons ensuite les concepts généralisables, le ROI, l’originalité ainsi que les premières implémentations d’envergure…
-

Cognitive Search: l’évolution des moteurs de recherche d’entreprise
« Data is the New Gold » : voici une citation que l’on a maintes fois vue et entendue quand il s’agit de parler de science des données ou d’intelligence artificielle. Ce blog se concentre sur les données non structurées et textuelles et une des nouvelles techniques qui permettent d’extraire « l’or » contenu dans celles-ci. Les entreprises et organisations disposent en effet d’une grande…
-
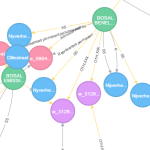
Sept (bonnes) raisons d’utiliser une Graph Database
Ces dernières années, les bases de données orientées graphes (ou Graph DB, présentées dans nos blogs précédents [1, 2]), et plus généralement les bases de données NoSQL, ont énormément gagné en popularité et en visibilité. Pour preuve, Neo4j, le leader actuel du marché des Graph Databases, apparaît depuis 2014 dans le “Magic Quadrant for Operational Database Management Systems (DBMS)“, et…
-
Le marché du travail salarié en Belgique : une analyse réseau (partie 3/3)
Dans le premier article de notre série consacrée à l’analyse réseau du marché du travail en Belgique, nous avons présenté les données constituant le graphe (ou réseau) de Dimona, sur lequel se base cette série de trois articles, et montré quelques métriques, permettant par exemple d’évaluer le nombre de personnes actives à un moment donné, ou le nombre d’employeurs par…
-
Le marché du travail salarié en Belgique : une analyse réseau (partie 2/3)
Dans notre article précédent, nous avons montré quelques éléments d’analyse réseau appliquée à la base de données “Dimona”, qui recense, en Belgique, les relations de travail entre tous les employeurs et leurs employés. Nous y avons principalement analysé la notion de degré, permettant de voir le nombre d’employeurs par employé, et le nombre d’employés par employeur. Nous allons maintenant examiner…
-
Le marché du travail salarié en Belgique : une analyse réseau (partie 1/3)
Le marché du travail nécessite partout une attention constante de la part des autorités. Cette attention ne peut se faire qu’en ayant une connaissance descriptive approfondie du secteur, raison pour laquelle de nombreuses analyses statistiques sont faites en permanence dans ce domaine (ONSS, Statbel, SPF Emploi, Actiris…). Si ces analyses sont incontournables, nous avons montré dans nos précédents blogs [à…
Keywords:
analytics Artificial intelligence big data blockchain BPM chatbot cloud computing cost cutting cryptography data center data quality EDA egov Event GIS governance Information management Machine Learning Managing IT costs methodology Mobile Natural Language Processing Open Source Privacy Productivity Security social software design software engineering standards