[FR]
-

Data Quality & « back tracking » : depuis les premières expérimentations à la parution d’un Arrêté Royal
Thomas Redman compare une base de donnée à un lac, alimenté par des flux aquatiques continus. La métaphore illustre l’approche qui sera évoquée dans ce blog en vue d’améliorer la qualité des données. 1. Les enjeux de la qualité des données : rappel et exemple En effet, nettoyer “à l’infini” le fond du lac (via des algorithmes de “data cleansing”) n’est pas efficace…
-
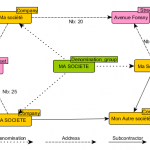
Gérer les doublons dans une Graph Database
Dans nos blogs précédents (1, 2, 3, 4), nous avons mis en évidence le fait que les structures de graphes étaient très adaptées à la recherche de comportement frauduleux. En étant plongés quotidiennement dans des données issues de diverses bases de données officielles, nous sommes également confrontés en permanence à la présence d’une grande quantité d’information de mauvaise qualité (1,…
-

Portal vs message broker – 2 approches complémentaires
Dans un récent projet impliquant de nombreux partenaires devant s’échanger des données, le débat broker versus portal (ou portail en français) â fait l’objet de nombreuses discussions. Avec, comme à l’habitude, sur des sujets aussi stratégiques, une tendance malheureuse à polariser les discussions. Cette polarisation n’a pas lieu d’être : chacune de ces approches a sa part de valeur ajoutée pour…
-

La préservation du patrimoine scientifique à l’heure du numérique (31/01/2018, ULB)
Rencontre « Data quality » FNRS-ULB-Smals le 31/01/2018 à l’Université libre de Bruxelles La prochaine réunion du groupe de contact FNRS « Analyse critique et amélioration de la qualité de l’information numérique » se tiendra le mercredi 31 janvier 2018 à 14h00 à l’Université libre de Bruxelles (auditoire AY2.108, bâtiment A, campus du Solbosch). Téléchargez les slides d’Isabelle Boydens (1MB) et d’Anthony Leroy (16MB). Pluridisciplinaire, le groupe se situe…
-

Quantum technology: révolution ou déclin de la sécurité informatique?
La technologie quantique est-elle le futur du XXIe siècle? C’est la question que se posent nombre de scientifiques à l’heure actuelle. Malgré cette incertitude, la plupart sont d’accord sur un point : la technologie quantique va amener une révolution scientifique sans précédent. En ce qui concerne la sécurité informatique, la technologie quantique est la bombe à retardement qui va casser une…
-
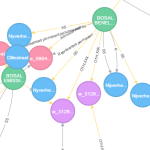
Bases de données relationnelles… adéquates pour des relations ?
(Avertissement : cet article nécessite des connaissances élémentaires en bases de données). Les bases de données relationnelles servent à représenter des relations. Cette affirmation peut sembler un euphémisme. Pourtant, à y regarder de plus près, les choses ne sont peut-être pas si évidentes. Essayons de comprendre pourquoi au travers de quelques exemples simples. Bases de données relationnelles et relations Supposons d’abord…
-

Tokenization : méthode moderne pour protéger les données
En sécurité de l’information, les protections périphériques ne sont plus suffisantes pour protéger correctement les données d’un système. Les attaquants arrivent tôt ou tard à pénétrer le système et à accéder directement aux données. C’est pourquoi il est donc primordial de pouvoir faire appel à des techniques pour sécuriser directement les données. Les plus connues à l’heure actuelle sont le chiffrement…
-
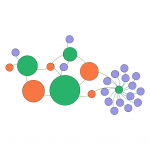
Un fraudeur ne fraude jamais seul, partie 2
Dans l’article précédent, nous expliquions plusieurs scénarios dans lesquels des données de type “réseau” (à savoir un ensemble d’entités ou nœuds, comme des personnes ou des sociétés, reliées par un ensemble de liens ou relations, comme une relation de travail ou un lien d’amitié) sont collectées, et dans lesquels on cherche à identifier soit des structures particulières (comme dans le cas de spider constructions), soit des entités…
-
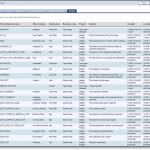
Comment construire un data dictionary ?
Rappel : pourquoi un data dictionary ? La raison d’être d’un data dictionary réside dans la nécessité de construire un vocabulaire commun entre tous les acteurs d’un projet sur l’aspect particulier des données. Le partage d’un vocabulaire commun facilite la communication entre tous les acteurs du projet. Il constitue un facteur clé de succès pour éviter les ambiguïtés dues à des interprétations…
-

SmalsBeSign: signer en toute sécurité sans se faire mal aux doigts
Dans un précédent blog, j’évoquais la problématique du “batch signing” (“signature en lot” en français). Lorsqu’un utilisateur souhaite signer 100 documents avec sa carte eID belge, soit il tape manuellement son code PIN 100 fois, soit il utilise un logiciel qui met en cache son code PIN, ce dernier étant ensuite utilisé automatiquement par le logiciel pour signer un à…
Keywords:
analytics Artificial intelligence big data blockchain BPM chatbot cloud computing cost cutting cryptography data center data quality EDA egov Event GIS governance Information management Machine Learning Managing IT costs methodology Mobile Natural Language Processing Open Source Privacy Productivity Security social software design software engineering standards