Research blog
-

Introduction à l’informatique confidentielle
On considère généralement que les données peuvent être dans trois états. Celles stockées, par exemple sur un disque dur ou dans une base de données, sont dites « au repos », celles envoyées d’un ordinateur à un autre, par exemple via un réseau, sont « en mouvement, » et les données traitées par le microprocesseur sont « en cours d’utilisation
-

Organisation pratique d’ateliers d’IA
Il y a un intérêt pour l’intelligence artificielle (IA) dans les différentes institutions de la sécurité sociale et de nombreuses initiatives ont vu le jour chez nos membres. En soutien à ces initiatives, Smals organise pour ses membres une série d’ateliers visant à mener en collaboration avec les agents une réflexion sur l’utilisation de l’intelligence
-
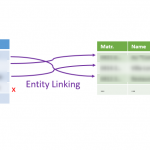
Dédoublonnage et couplage : comment ça marche ?
Dans un article précédent à propos du webscraping, nous avons été confrontés à une situation où nous obtenions une liste de commerces, avec un nom et une adresse. Nous voulions, pour chacun de ces commerces, le lier à une liste de commerces “officielle”, à savoir celle de la Banque Carrefour des Entreprises, ayant une structure
-

Web3 in Wonderland
Het jongste buzzword in blockchain-land luistert naar de naam Web3. Het zou de logische volgende stap zijn in de evolutie van het Internet, met blockchain-technologie als ruggengraat. Web3 belooft een gedecentraliseerde toekomst, weg van de hegemonie der platform-mastodonten zoals Facebook en Amazon. Burgers zouden voortaan via een wallet op hun smartphone of computer volledige controle
-

Haystack – NLP framework for document search and QA
Haystack est une librairie Python open-source qui permet la construction de systèmes de questions-réponses (QA) et de systèmes de recherche sémantique de documents basé sur des modèles de langage type Transformer. Cette librairie intègre d’autres projets open-source tels que Elasticsearch, FAISS et HuggingFace. Haystack is een open-source Python library die toelaat om question answering en
-
De vier gezichten van EDA
Event Driven Architecture (EDA) is niet meer weg te schrijven uit moderne software-architectuur. Maar wanneer ben je nu effectief EDA aan het gebruiken? Soms kan het zijn dat dit paradigma in je software-systeem zit, zonder dat je er erg in hebt. En daarnaast gebeurt het ook vaak dat een architect zegt dat zijn systeem EDA
-

ChatGPT: een eerste indruk vanuit de publieke sector
De stroom van indrukwekkende voorbeelden en creatieve toepassingen van ChatGPT die ons passeert op sociale media is haast eindeloos. Wat betekent dit nu voor de publieke sector, waar kunnen we impact verwachten en waar zal het zo’n vaart niet lopen?
-

« Synthetic Data » – Webinar by Smals Research (december 01,2022)
“Fake it till you make it” : une introduction aux données synthétiques (Nederlandstalige tekst : zie onder) Un ensemble de données synthétiques est un ensemble de données fictives qui reproduit le plus fidèlement possible les caractéristiques d’un ensemble de données réelles. Un ensemble de données synthétiques correctement constitué peut, comme il s’agit de données purement fictives, être
-

Fake it till you make it – an introduction to synthetic data
Slides van de webinar voor Smals Academy op 01/12/2022 (texte français : voir ci-dessous) Een synthetische dataset is een fictieve dataset die de kenmerken van een echte dataset zo goed mogelijk nabootst. Een correct samengestelde synthetische dataset kan, omdat het om louter fictieve gegevens gaat, probleemloos gedeeld, hergebruikt of gepubliceerd worden. Zo kan de toegang tot
-
Tabula – Pdf-file Table Extractor
Tabula is een eenvoudige doch goed werkende tool om tabellen uit een pdf-bestand te halen. OCR is niet ondersteund, maar tabellen worden vrij goed automatisch gedetecteerd en de tool is ook goed integreerbaar. Tabula est un outil simple mais puissant pour extraire des tableaux d’un fichier PDF. L’OCR n’est pas pris en charge, mais les
Keywords:
analytics annexe_category Artificial intelligence big data blockchain BPM chatbot cloud computing cost cutting cryptography data center data quality development EDA egov Event GIS Knowledge Graph Machine Learning methodology Mobile Natural Language Processing NLP Open Source PaaS Privacy Productivity quantum computing Security software design